List items
Items from the current list are shown below.
Blog
3 Dec 2023 : Day 96 #
This morning I'm on the train headed for work. It's a very cold and frosty morning — it could almost be Finland — and my development environment isn't ideal for SSH-ing into my phone, but it's not busy so I've experienced worse!
We finished up yesterday with the realisation that search provider installation was being blocked by changes that prevented the OpenSearch configuration being loaded from disk. The download scheme was being checked by a regex that only allowed "https" to be used.
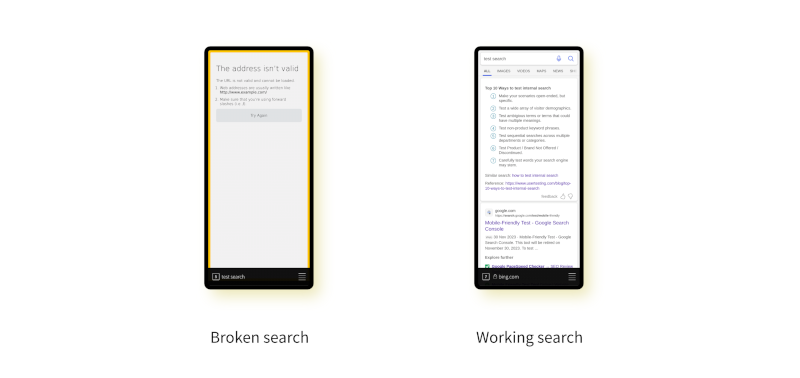
This morning I overrode the regex to allow the "file" scheme to be used. Here's the resulting output.
But not only that, now the search functionality is back too!
This is great, but I'm a little nervous about the changes: there were some big changes made to remove the "file" scheme and I'll need to look carefully into why this was and whether it's safe to work around it. The changes I've made to allow it are minimal and I'd feared I'd have to restore far more of the changes in changeset D104010.
The good news is I can stop debugging my phone while I travel. Looking like someone from Mr Robot on the train isn't something I'm totally comfortable with! I'll return to these changes and put together a proper fix this evening.
[...]
It's evening now and time to turn the hacky changes I made earlier into a proper fix. Before I do that I want to reflect on a discussion with Ville Nummela on Mastodon. Ville — vige — is one of my ex-colleagues from Jolla and, you won't be surprised to hear, someone I have a lot of time and respect for. Ville pointed out that OpenSearch is still supported on Firefox, so if it's causing trouble like this for our version for the sailfish-browser, shouldn't it cause similar issues on Firefox?
This is such a good question and something I should have thought about and investigated over the last few days. It turns out there is a good answer and that, as you might expect, Firefox isn't downloading the OpenSearch provider XML files every time it starts up.
It took me a while to dig through the code, but the answer is in the SearchSettings.jsm file from upstream gecko. This provides two crucial methods: SearchSettings._write() and SearchSettings.get(). The first of these writes the OpenSearch providers out to disk, but not in their original XML format, but rather in a compressed JSON format. The second of these reads them back in again from disk.
The reason why it's _write() and not write() is that it's not supposed to be called directly. Instead it's called automatically via _delayedWrite() when something changes:
This also helps answers my earlier question about why loading of these XML files was restricted to the https scheme. The good news is that the change I've made is probably fine, it just isn't being used by Firefox any more. But I've also created ticket #1048 suggesting that we update our code to move to the Firefox approach.
Now back to the changes we've already made. The fixes I added to allow loading using the file scheme as well as https are still just hacked onto my phone. With these added the output from the search installation at start up looks much cleaner:
Nevertheless to ensure everything has been changed correctly I'll leave the build running overnight and install it tomorrow morning.
One thing you may notice is that the sAllowKeyWordURL isn't actually how it's supposed to be for a proper fix. Rather than setting this statically to be true we should really be reading the value of the keyword.enabled preference. In fact there are a whole bunch of preferences like this that we need to fix.
Because of this it makes more sense to do them all together rather than finding a solution for just this particular case. So maybe fixing all of these preferences would make a sensible task to start tomorrow.
Step by step, slowly but surely, the browser functionality is improving where we're getting to the point that the browser is quite usable. But clearly there is still more to be done.
If you'd like to catch up on all the diary entries, they're all available on my Gecko-dev Diary page.
We finished up yesterday with the realisation that search provider installation was being blocked by changes that prevented the OpenSearch configuration being loaded from disk. The download scheme was being checked by a regex that only allowed "https" to be used.
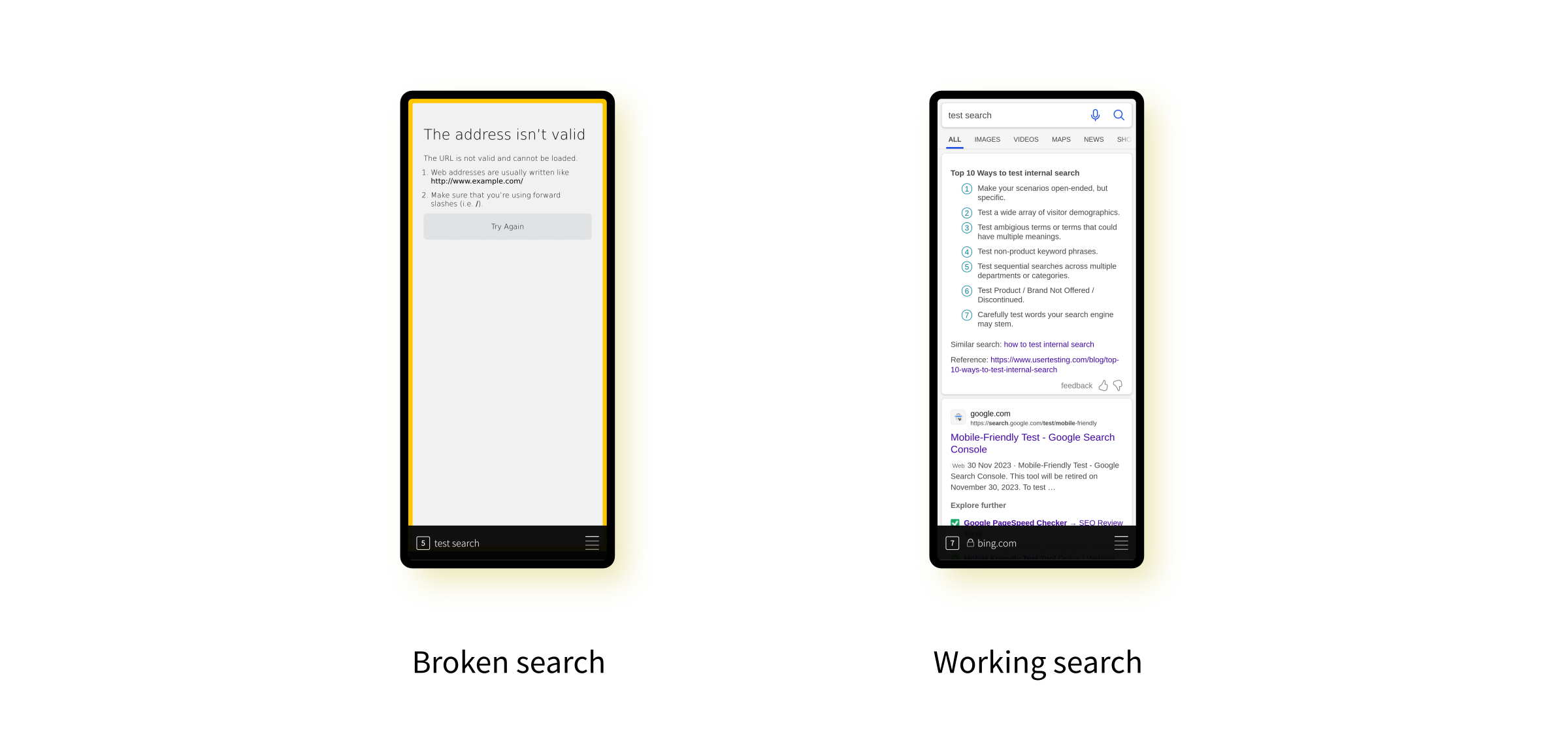
This morning I overrode the regex to allow the "file" scheme to be used. Here's the resulting output.
Frame script: embedhelper.js loaded
SEARCH: getFixupURIInfo() fixupFlags: 8
SEARCH: engine num: 0
SEARCH: addOpenSearchEngine():
file:///usr/lib64/mozembedlite/chrome/embedlite/content/bing.xml
SEARCH: stack start
addOpenSearchEngine@resource://gre/modules/SearchService.jsm:1869:10
observe@file:///usr/lib64/mozembedlite/components/EmbedLiteSearchEngine.js:56:29
SEARCH: stack end
SEARCH: _install: uri:
file:///usr/lib64/mozembedlite/chrome/embedlite/content/bing.xml
SEARCH: _install: Downloading engine from:
file:///usr/lib64/mozembedlite/chrome/embedlite/content/bing.xml
This shows that the code is getting past the check, but not much else. And crucially, the search providers still aren't being installed correctly. We're also getting the following errors a little later:
[JavaScript Error: "TypeError: this._engineToUpdate is null"
{file: "resource://gre/modules/OpenSearchEngine.jsm" line: 138}]
_onLoad@resource://gre/modules/OpenSearchEngine.jsm:138:5
onStopRequest@resource://gre/modules/SearchUtils.jsm:92:10
This error is actually coming from one of the debug output lines I added myself:
dump("SEARCH: _onLoad: Downloaded engine from:" + this._engineToUpdate.name + "\n");
I've removed the reference to this._engineToUpdate from this line and now it passes correctly.But not only that, now the search functionality is back too!
This is great, but I'm a little nervous about the changes: there were some big changes made to remove the "file" scheme and I'll need to look carefully into why this was and whether it's safe to work around it. The changes I've made to allow it are minimal and I'd feared I'd have to restore far more of the changes in changeset D104010.
The good news is I can stop debugging my phone while I travel. Looking like someone from Mr Robot on the train isn't something I'm totally comfortable with! I'll return to these changes and put together a proper fix this evening.
[...]
It's evening now and time to turn the hacky changes I made earlier into a proper fix. Before I do that I want to reflect on a discussion with Ville Nummela on Mastodon. Ville — vige — is one of my ex-colleagues from Jolla and, you won't be surprised to hear, someone I have a lot of time and respect for. Ville pointed out that OpenSearch is still supported on Firefox, so if it's causing trouble like this for our version for the sailfish-browser, shouldn't it cause similar issues on Firefox?
My understanding is that Firefox still allows adding OpenSearch providers from websites - that's why https is still there. Do they reload the providers via https every time?
This is such a good question and something I should have thought about and investigated over the last few days. It turns out there is a good answer and that, as you might expect, Firefox isn't downloading the OpenSearch provider XML files every time it starts up.
It took me a while to dig through the code, but the answer is in the SearchSettings.jsm file from upstream gecko. This provides two crucial methods: SearchSettings._write() and SearchSettings.get(). The first of these writes the OpenSearch providers out to disk, but not in their original XML format, but rather in a compressed JSON format. The second of these reads them back in again from disk.
The reason why it's _write() and not write() is that it's not supposed to be called directly. Instead it's called automatically via _delayedWrite() when something changes:
// nsIObserver
observe(engine, topic, verb) {
switch (topic) {
case SearchUtils.TOPIC_ENGINE_MODIFIED:
switch (verb) {
case SearchUtils.MODIFIED_TYPE.ADDED:
case SearchUtils.MODIFIED_TYPE.CHANGED:
case SearchUtils.MODIFIED_TYPE.REMOVED:
this._delayedWrite();
break;
}
break;
[...]
Here are the first few lines including docstrings of each of the methods for reference. First for writing out to disk:
/**
* Writes the settings to disk (no delay).
*/
async _write() {
if (this._batchTask) {
this._batchTask.disarm();
}
let settings = {};
// Allows us to force a settings refresh should the settings format change.
settings.version = SearchUtils.SETTINGS_VERSION;
settings.engines = [...this._searchService._engines.values()];
settings.metaData = this._metaData;
[...]
Second for reading in from disk. This is the part that replaces the code that we had to patch to allow loading of the XML file:
/**
* Reads the settings file.
*
* @param {string} origin
* If this parameter is "test", then the settings will not be written. As
* some tests manipulate the settings directly, we allow turning off writing to
* avoid writing stale settings data.
* @returns {object}
* Returns the settings file data.
*/
async get(origin = "") {
let json;
await this._ensurePendingWritesCompleted(origin);
try {
let settingsFilePath = PathUtils.join(
await PathUtils.getProfileDir(),
SETTINGS_FILENAME
);
[...]
In both of these snippets of code we can see this important constant, which is the name of the file to save out or load in and which we can see initialised at the top of the same file:
const SETTINGS_FILENAME = "search.json.mozlz4";If we look inside the ESR 91 settings folder we can see that this file is indeed being saved out:
ls -l ~/.local/share/org.sailfishos/browser/.mozilla/search.json.mozlz4 -rw-rw-r-- 1 defaultu defaultu 17715 Dec 2 20:03 search.json.mozlz4We can compare this to the XML files that sailfish-browser is saving out to be loaded at start up to reinitialise the OpenSearch providers:
$ ls -l ~/.local/share/org.sailfishos/browser/searchEngines/ total 16 -rw-rw-r-- 1 defaultu defaultu 1949 Dec 2 19:08 duckduckgo.com.xml -rw-rw-r-- 1 defaultu defaultu 688 Dec 2 19:05 forum.sailfishos.org.xml -rw-rw-r-- 1 defaultu defaultu 549 Nov 26 14:48 github.com.xml -rw-rw-r-- 1 defaultu defaultu 3493 Dec 2 19:06 www.openstreetmap.org.xmlIn conclusion, Firefox is using a different mechanism to save out and load in the search providers. The file is being saved out to our profile, but at no point are we loading it back in. Updating the code to load it in using the Firefox approach would be a nice fix: it would mean we wouldn't have to patch the XML loading code, it would mean less to maintain in future and it would also mean we're not saving out the same data to two different places.
This also helps answers my earlier question about why loading of these XML files was restricted to the https scheme. The good news is that the change I've made is probably fine, it just isn't being used by Firefox any more. But I've also created ticket #1048 suggesting that we update our code to move to the Firefox approach.
Now back to the changes we've already made. The fixes I added to allow loading using the file scheme as well as https are still just hacked onto my phone. With these added the output from the search installation at start up looks much cleaner:
SEARCH: engine num: 6 SEARCH: engine name: Bing SEARCH: engine name: DuckDuckGo SEARCH: engine name: GitHub SEARCH: engine name: Yandex SEARCH: engine name: Google SEARCH: engine name: Yahoo SEARCH: get defaultEngine: SEARCH: get defaultEngine: SEARCH: EmbedLiteSearchEngine setdefault received SEARCH: EmbedLiteSearchEngine engine: DuckDuckGoAfter removing all the debug output I'm left with just four simple changes. First in EmbedLiteViewChild.cpp we have this:
-static bool sAllowKeyWordURL = false; +static bool sAllowKeyWordURL = true;In OpenSearchEngine.jsm, mimicking the approach originally used to allow both "http" and "ftp" schemes, I've adjusted it to be both "http" and "file" schemes:
- if (!/^https?$/i.test(loadURI.scheme)) {
+ if (!/^(?:https?|file)$/i.test(loadURI.scheme)) {
Both of these changes are in the gecko-dev repository, but there are also changes needed in the embedlite-components repository as well. In EmbedLiteSearchEngine.js:
- Services.search.addEngine(data.uri, null, data.confirm).then( + Services.search.addOpenSearchEngine(data.uri, null).then(And finally in PromptService.js:
+const { ComponentUtils } = ChromeUtils.import("resource://gre/modules/ComponentUtils.jsm");
[...]
-this.NSGetFactory = XPCOMUtils.generateNSGetFactory([PromptService, AuthPromptAdapterFactory]);
+this.NSGetFactory = ComponentUtils.generateNSGetFactory([PromptService, AuthPromptAdapterFactory]);
Apart from the first instance all of these changes are to the JavaScript. Since I've already compiled the single small C++ change I can, in effect, make all of these changes now without having to rebuild gecko.Nevertheless to ensure everything has been changed correctly I'll leave the build running overnight and install it tomorrow morning.
One thing you may notice is that the sAllowKeyWordURL isn't actually how it's supposed to be for a proper fix. Rather than setting this statically to be true we should really be reading the value of the keyword.enabled preference. In fact there are a whole bunch of preferences like this that we need to fix.
Because of this it makes more sense to do them all together rather than finding a solution for just this particular case. So maybe fixing all of these preferences would make a sensible task to start tomorrow.
Step by step, slowly but surely, the browser functionality is improving where we're getting to the point that the browser is quite usable. But clearly there is still more to be done.
If you'd like to catch up on all the diary entries, they're all available on my Gecko-dev Diary page.
Comments
Uncover Disqus comments